
数据表创建
---学生成绩表
create table t_student(
ID number(10),
name varchar2(100),
score number(10),
class_id number(10)
);
insert into t_student values (1,'A',75,1);
insert into t_student values (2,'B',78,2);
insert into t_student values (3,'C',74,1);
insert into t_student values (4,'D',85,2);
insert into t_student values (5,'E',80,1);
insert into t_student values (6,'F',82,2);
insert into t_student values (7,'G',98,1);
insert into t_student values (8,'H',90,2);
insert into t_student values (9,'I',90,2);
---班级表
create table t_class(
ID number(10),
name varchar2(100)
);
insert into t_class values (1,'一班');
insert into t_class values (2,'二班');
问题:查询两个班前三名的学生成绩?
select *
from (
select name, score, class_id, rank() over (partition by class_id order by score desc) as sm
from t_student
)
where sm < 4;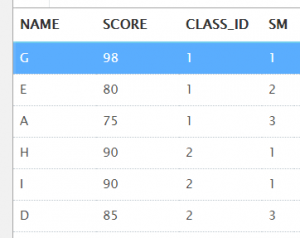
关于over函数说明
rank () over ( [query_partition_clause] order_by_clause )
dense_rank ( ) over ( [query_partition_clause] order_by_clause )
可实现按指定的字段分组排序,对于相同分组字段的结果集进行排序,
其中 partition by 为分组字段,order by 指定排序字段
over不能单独使用,要和分析函数:rank(), dense_rank(), row_number()等一起使用。
其参数:over(partition by columnname1 order by columnname2)
含义:按columname1指定的字段进行分组排序,或者说按字段columnname1的值进行分组排序
- over函数的写法:
over(partition by class order by sroce) 按照sroce排序进行累计,order by是个默认的开窗函数,按照class分区 - 开窗的窗口范围:
over(order by sroce range between 5 preceding and 5 following):窗口范围为当前行数据幅度减5加5后的范围内的。
over(order by sroce rows between 5 preceding and 5 following):窗口范围为当前行前后各移动5行。
与over()函数结合的函数的介绍
①查询每个班的第一名的成绩
select *
from (
select t.name, t.class_id, t.score, rank() over (partition by t.class_id order by t.score desc) as mm
from t_student t
)
where mm = 1;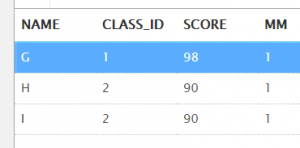
select *
from (
select t.name, t.class_id, t.score, row_number() over (partition by t.class_id order by t.score desc) as mm
from t_student t
)
where mm = 1;
注意:在求第一名成绩的时候,不能用row_number(),因为如果同班有两个并列第一,row_number()只返回一个结果
②rank()和dense_rank()可以将所有的都查找出来,rank可以将并列第一名的都查找出来;rank()和dense_rank()区别:rank()是跳跃排序,有两个第二名时接下来就是第四名
select *
from (
select name, score, class_id, rank() over (partition by class_id order by score desc) as sm
from t_student
)
where sm < 4;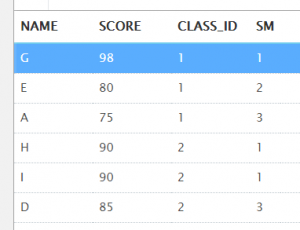
select *
from (
select name, score, class_id, dense_rank() over (partition by class_id order by score desc) as sm
from t_student
)
where sm < 4;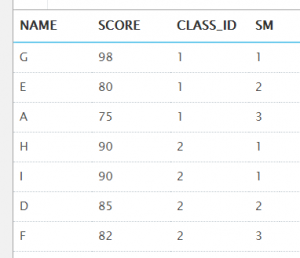
③sum()和over()的使用,根据班级进行分数求和
select t.name, t.class_id, t.score,
sum(t.score) over (partition by t.class_id order by t.score desc) as mm
from t_student t;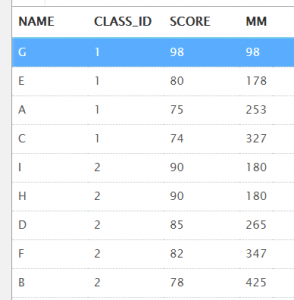
④first_value()和over()、last_value()和over()的使用,分别求出第一个和最后一个成绩
select t.name, t.class_id, t.score,
first_value(t.score) over (partition by t.class_id order by t.score desc) as mm
from t_student t;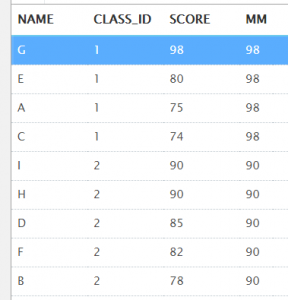
select t.name, t.class_id, t.score,
last_value(t.score) over (partition by t.class_id order by t.score desc) as mm
from t_student t;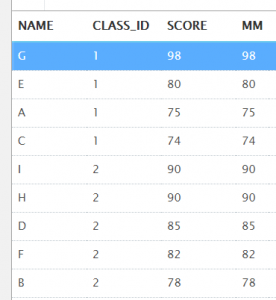
正常情况下,last_value()值,CLASS_ID为1的MM,不应该是74吗?
其实可以这样去理解:last_value()默认统计范围是 rows between unbounded preceding and current row,也就是取当前行数据与当前行之前的数据的比较。
那么,如何像first_value()那样直接在每行数据中显示最后的那个数据呢?
在order by 条件的后面加上语句:rows between unbounded preceding and unbounded following
select t.name, t.class_id, t.score,
last_value(t.score) over (partition by t.class_id order by t.score desc rows between unbounded preceding and unbounded following) as mm
from t_student t;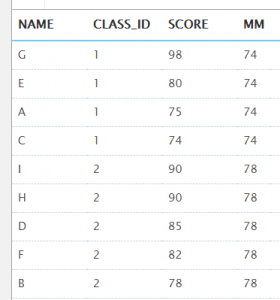
其他函数类似用法
count() over(partition by ... order by ...):求分组后的总数。
max() over(partition by ... order by ...):求分组后的最大值。
min() over(partition by ... order by ...):求分组后的最小值。
avg() over(partition by ... order by ...):求分组后的平均值。
lag() over(partition by ... order by ...):取出前n行数据。
lead() over(partition by ... order by ...):取出后n行数据。
ratio_to_report() over(partition by ... order by ...):Ratio_to_report() 括号中就是分子,over() 括号中就是分母。
percent_rank() over(partition by ... order by ...):返回某列或某列组合后每行的百分比排序











